Member Info
- Ruokun Niu rniu8@gatech.edu
- Yisu Ma yma391@gatech.edu
- Jiayuan Fu jfu94@gatech.edu
- Yangxiaojun Zhang yzhang3449@gatech.edu
- Zhiyi Li zli879@gatech.edu
Project proposal
Background
It is undoubtedly that investment in the real estate industry has proven to be lucrative in the past decade. For many who are purchasing properties for personal uses instead of investing, the continual rise in housing prices throughout the country is a daunting factor. Additionally, many home-buyers either do not have access to comprehensive information of the properties in a given region, or, more commonly, does not have the knowledge or ability to utilize such data to perform rational analysis.
As a group of undergraduate students who have obtained some knowledge in Machine Learning from CS 4641 and are about to graduate from university, we will soon encounter the challenge of selecting a desired property to rent/purchase. We are aiming to create a ML model that can accurately approximate the pricing for a house, given a set of information of the property (e.g location, size, # of bedrooms and etc.)
Dataset
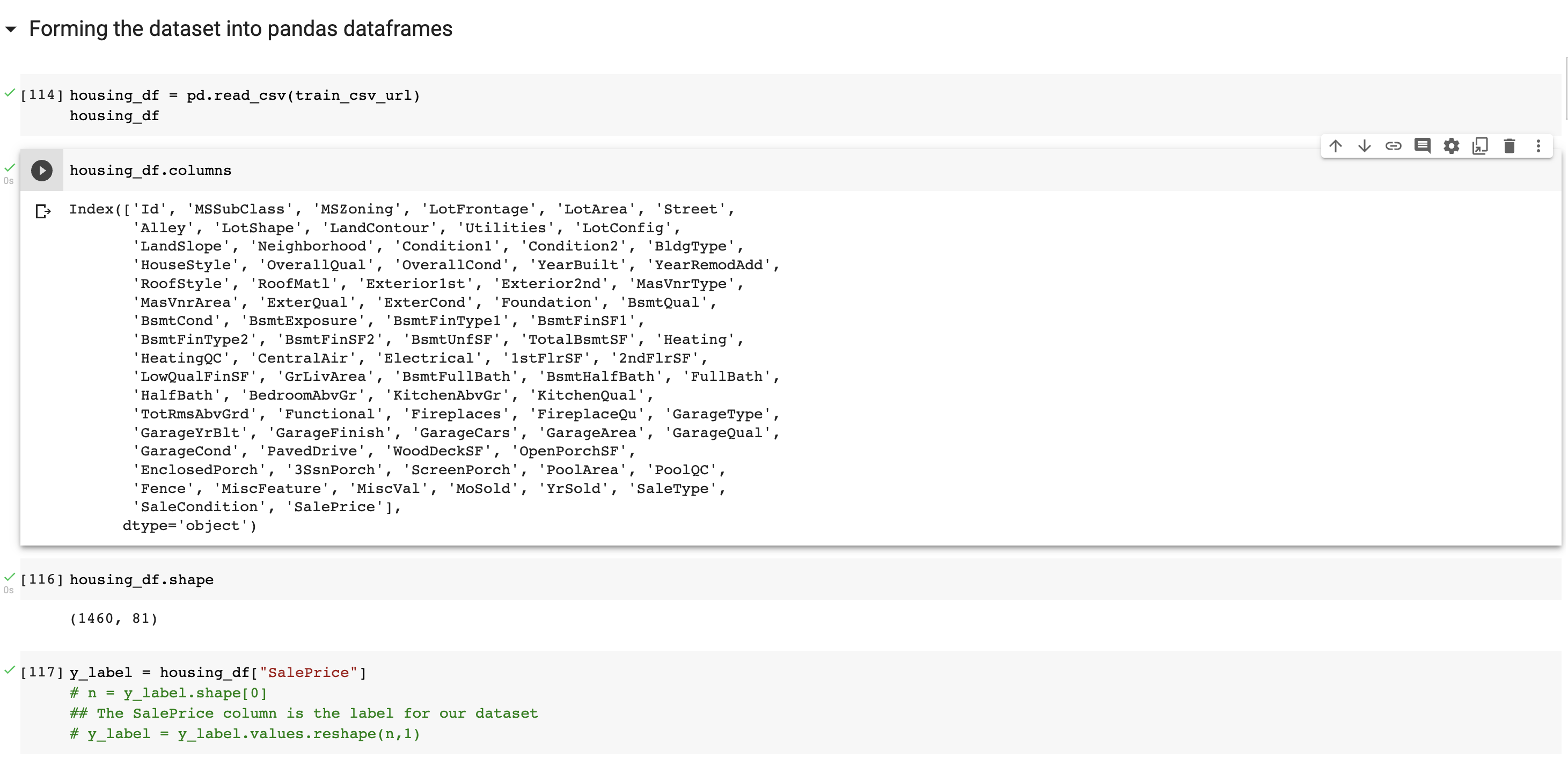
A link to the dataset that we will be using can be found here. Kaggle is an online community designed for data scientists and ML engineers. We will be using the data that is provided by Kaggle for one of its online competitions. The dataset contains 81 columns,or features. Since we are trying to predict the price of a given property, we will set SalePrice as the label for our dataset. Each datapoint also has an unique id. The remaining columns describe the conditions, locations and other characteristics of a given property. A detailed text file describing each of the features can be found here. Other than the training data, Kaggle also provides a set of data for testing the accuracy.
Model
The team is initially thinking about using a decision tree as our starting model choice. A decision tree is composed of a series of decisions that are made based on the features of the input dataset. At a given node in the decision tree, we will make a certain decision and traverse to the correct child of the current node based on the current value of the feature. For instance, as shown in the image below, if the current house has more than two bedrooms, we will predict a higher price for the property, vice versa.

A decision tree is a good starting point since it is relatively easy to implement and is comparatively less time-consuming. It is also effective at working with a large set of data. However, it does face the challenge of overfitting.
Another method that we can use is a random forest. Insteading making decisions based on one feature, random forest makes a decision based on several features by constructing several decision trees at the same time. According to research, random forests often generate more accurate results than decision trees, but constructing this model can be complex and the model can be time-expensive to run. The team will focus on implementing the decision tree model first.
Timeline
The proposed timeline for our project can be found here
Proposal Video
References:
- https://www.seattletimes.com/business/real-estate/five-takeaways-from-seattles-red-hot-2021-housing-market/#:~:text=The%20median%20price%20in%20Seattle,for%20%24650%2C000%2C%20up%2022.6%25
- https://www.kaggle.com/c/house-prices-advanced-regression-techniques/data
- https://www.upgrad.com/blog/random-forest-vs-decision-tree/#:~:text=A%20decision%20tree%20combines%20some,forest%20model%20needs%20rigorous%20training
- https://medium.com/@feng.cu/machine-learning-decision-tree-model-example-melbourne-house-price-prediction-83a22d16e50
Project Midterm Report
Part 1: Importing the dataset and the required packages
Importing all of the packages
Forming the dataset into pandas dataframes
Overall Price Distribution (Shown in a histogram):

Part 2: Data Cleaning and Feature Examination using EDA
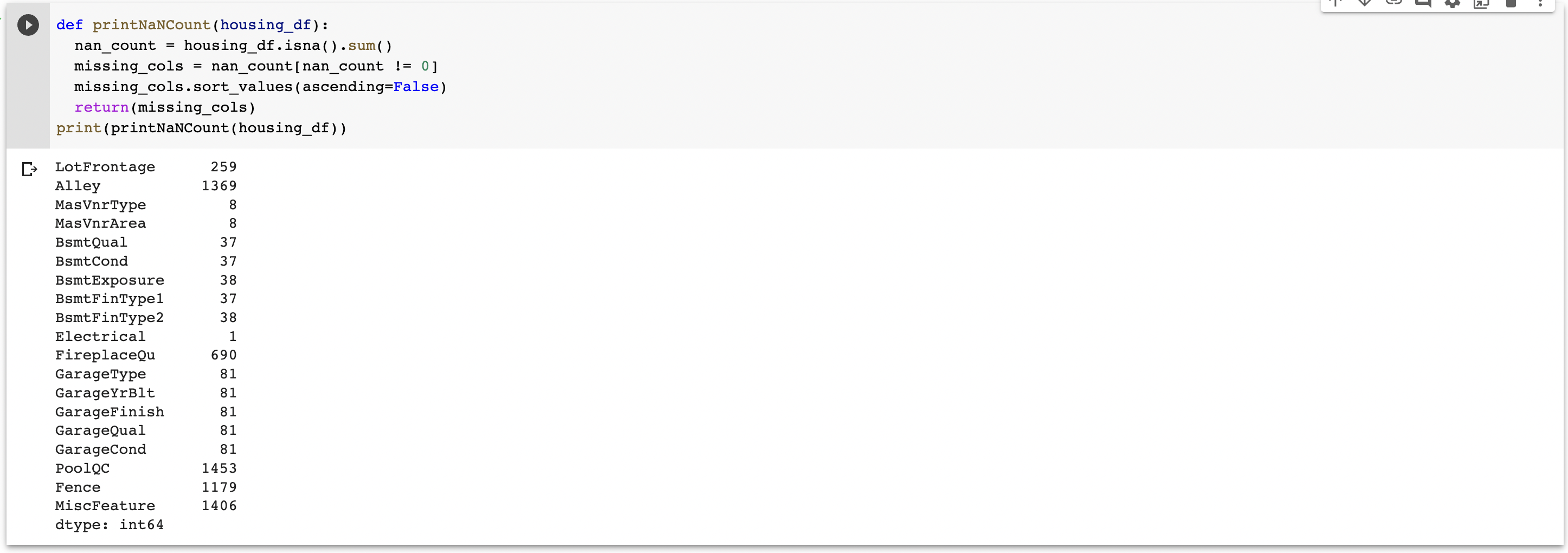
2.1 Checking for NaNs
For many of the features in our training dataset, there exist multiple NaNs throughout the dataset. However, for our dataset, a value of NaN does not mean an absence of data in every case.
In fact, depending on the feature/column, a value of NaN can either be a valid value, or can represent the absence of valid data. For instance, for the “PoolQC” (the pool quality feature), if the property does not contain a pool, then a value of NA will be used, highlighting the fact that this feature is not applicable. However, for some other features, NaN indicates the a value is missing. The code below prints all of the columns that contain a NaN value somewhere and the exact number of NaN values that the column contains.
Through manul inspection, we have created a dictionary for filling the missing information in our dataset. The keys to this dictionary are the column names in the dataset (only the ones that contain a NaN somewhere, and the values are the values that will replace the NaN.
For columns that contain purely numerical value, e.g. LotFrontage, a missing value, or Nan, will be replaced with 0. For Categorical columns that contain strings as values, NaN will be replaced by a short description of the type of feature that is missing for this column.
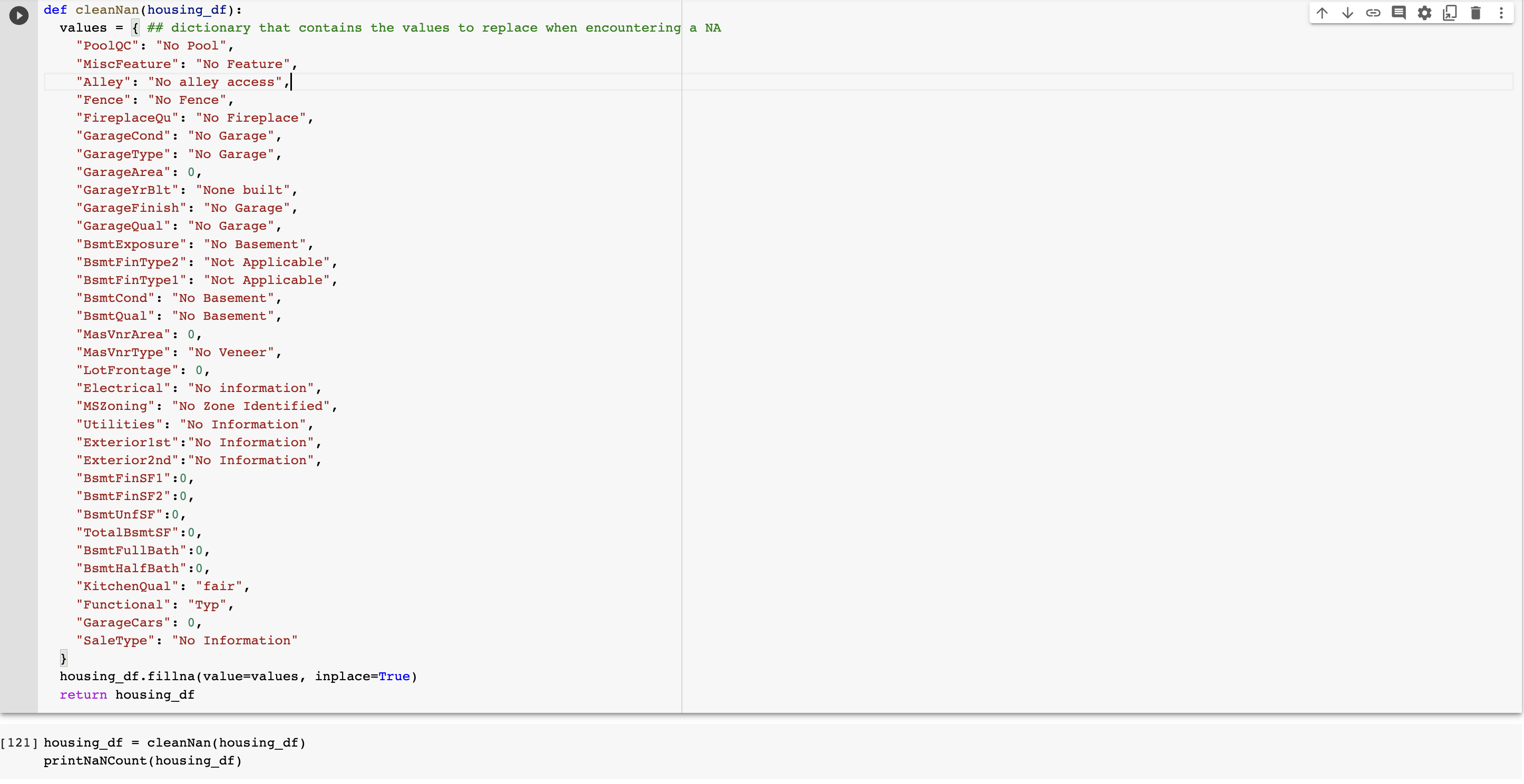
As shown in the code above, we are able to fill in the missing values in our training dataset.
2.2 Feature Engineering using EDA
** Used the information/tutorial from this site **
EDA stands for Exploratory Data Analysis and it is a data analysis approach that examines the relationship between the features. Since our dataset contains a lot of columns, it might be useful for us to examine the correlation/importance of every feature and drop the features that do not play a significant role in housing-price prediction.
This is a valid and essential approach as it reduces the complexity of our dataset (ultimately our models as well). Additionally, in reality, some features (e.g. number of bedrooms) of a house weigh more to the buyers than some other features (e.g. number of elevators).
The easiest way to visualize the correlation between the features is to use Sns’ heatmap, which presents the correlation as a heatmap matrix. The code snippet below performs this function.
{
plt.figure(figsize=(20, 32))
sns.heatmap(housing_df.corr(), annot_kws={"size": 8}, annot = True)
}
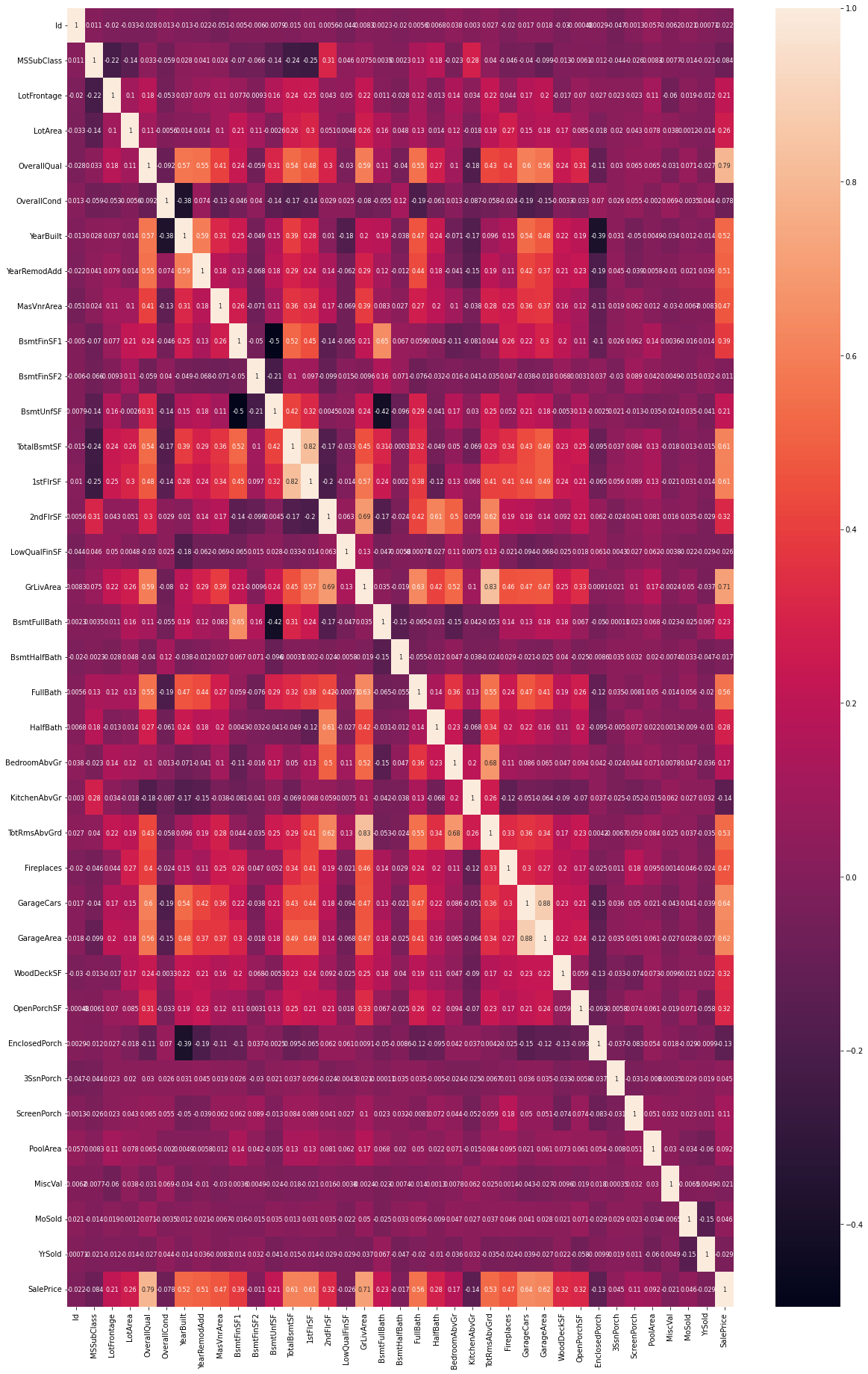
In the heat map above, a positive correlation is represented in lighter colors, whereas a negeative coorrelation is represented in the darker ones.
We now need to examine the correlation between the features and the label, SalePrice:

An easy way to reduce the number features in our dataset is to simply select two numerical thresholds, and only select the features where their correlations with the sale price (the absolute value) is within this boundary. For the initial attempt, we will set the minimum threshold to be 0.10 and the maximum threshold to be 0.90.
 We are able reduce from 81 columns (1 of the column is the label) into 25 columns. Notice that for our reduced dataset (train_X), all 25 columns are valid features. We are now able to proceed with building our model.
We are able reduce from 81 columns (1 of the column is the label) into 25 columns. Notice that for our reduced dataset (train_X), all 25 columns are valid features. We are now able to proceed with building our model.
Part 3: Decision Tree
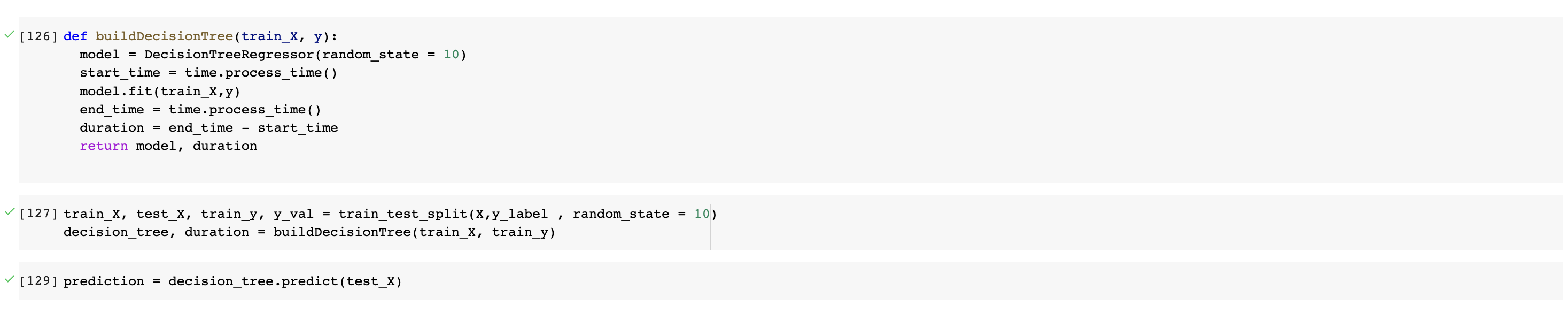
At this point of the course, we have not yet covered the topic of Decision Tree in lectures. As a result, most of our understandings on this topic come from online websites. For the actual implementation of our decision tree model, we will be using the class DecisionTreeRegressor from Scikit learn. A random seed of 10 will be used to start with.
We will also keep track the time that it took for the decision tree to train. This may be useful later on.
Part 4: Evaluation
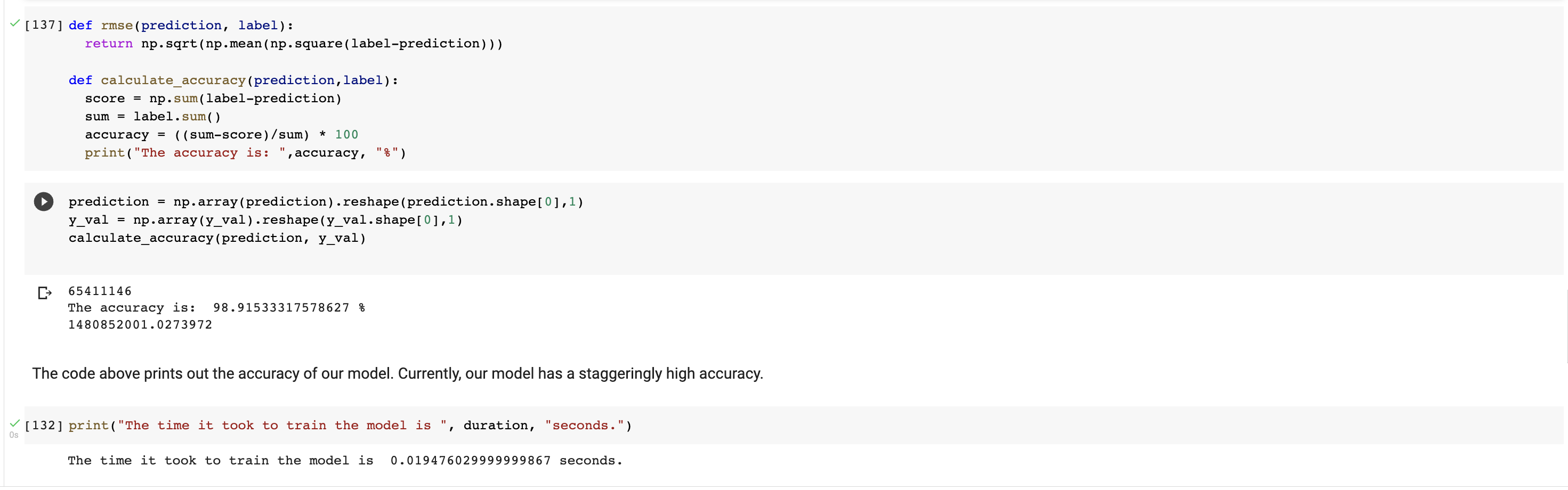
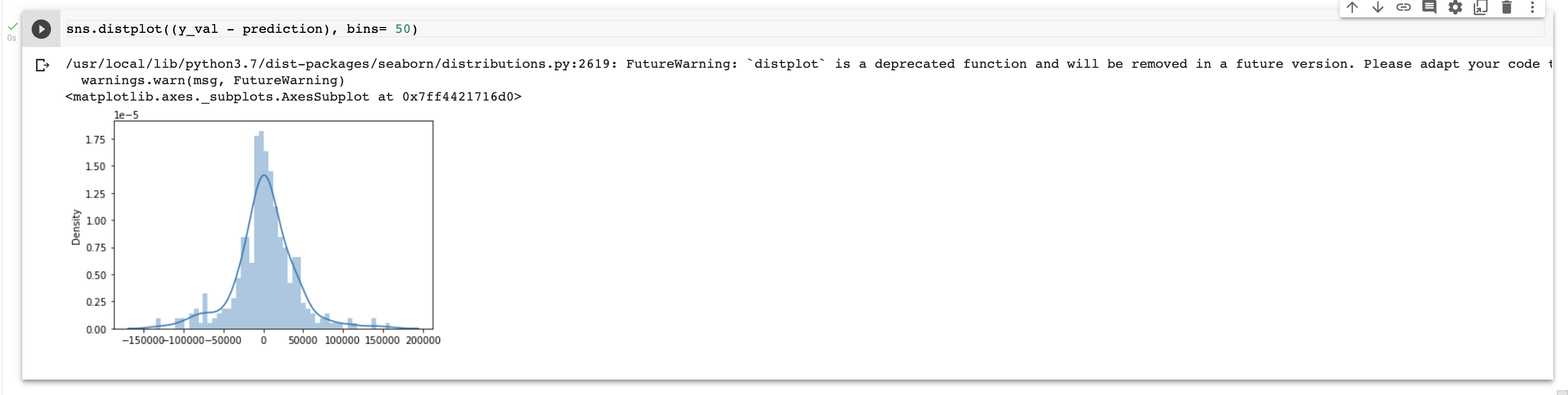
We will begin by determining the difference between the label and the prediction values. This difference will be used for calculating the accuracy.
Currently, we have an accuracy of 98.915%
Part 5: Goals/Directions for the next phase of the project
- Implement Random Forest
-
Include additional metrics/evaluations on Decision Tree Models from lectures
- Test, configure and determine the correlation thresholds that maximize the accuracy
- Configure the size of the dataset; use alternative ways, e.g. k-fold crooss validation, to test the accuracy
Project Final Report
*Background information, problem definition, data collection are the same as stated in proposal and midterm report.
After the midterm checkpoint, we have implemented two new models to train our housing data: Random Forest Model and Multiple Linear Regression Model to compare the accuracy between different models and try to find the most accurate way to predict the housing price. The key difference between a Random Forest and a Decision Tree is that a Random Forest uses Random sampling of training data points when building trees and it achieves higher accuracy in theory. We also use K-folds cross validation to test the accuracy of the decision tree model and multiple linear regression model.
Part 1: Random Forest
For random forest implementation, we choose to use the cleaned but un-reduced housing_df dataset. The dataset will have a shape of (1460, 81) with all 81 features. To make it compatible with the RandomForestClassifier, we use a encoder to transform it.
 After cleaning and transform the dataset, we are now able to use the RandomForestClassifier to generate the predicted results. We created the model with 1200 trees and a random state of 35.
After cleaning and transform the dataset, we are now able to use the RandomForestClassifier to generate the predicted results. We created the model with 1200 trees and a random state of 35.

Part 2: RF Evaluation
We have determined the difference between the label and the prediction values and calculate the model accuracy based on this difference. Currently, we have an accuracy of 98.628%.

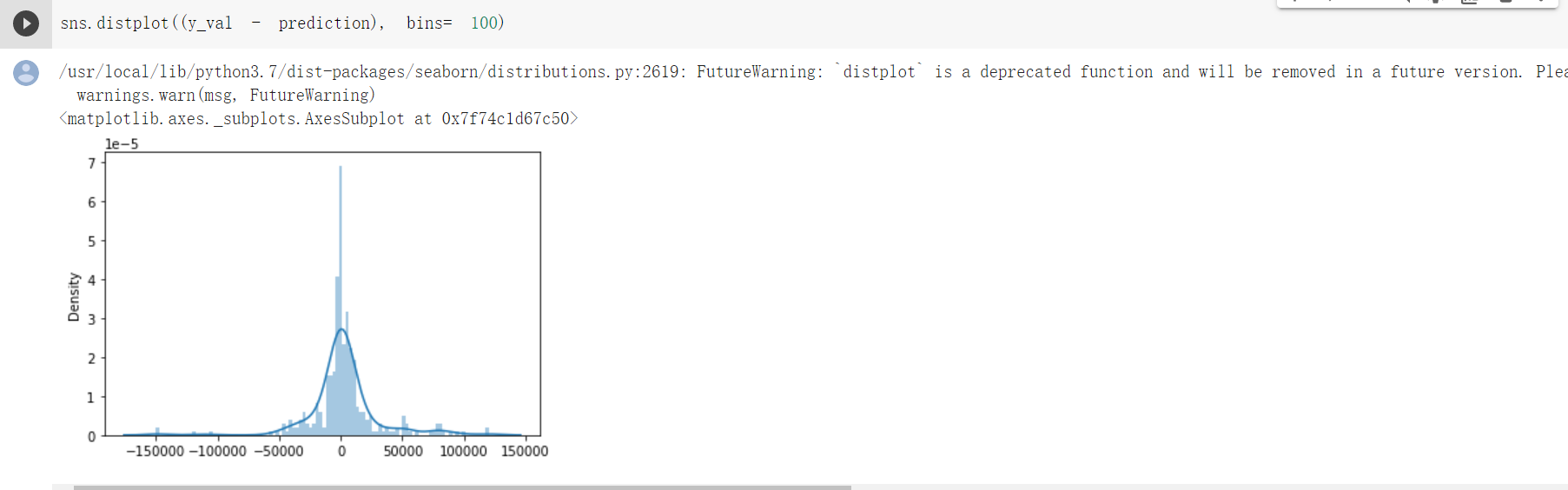
Part 3: Multiple Linear Regression
Multiple Linear regression model could use several explanatory variables to predict our sales price. During Phase II, we filtered our dataset and selected some of the features for a better machine learning training result. Here, we would again use the filtered dataset housing_df for our MLR model with only 25 features. We have presented several 2-D linear regression model from column “MasVnrArea” and “YearBuilt” proving that linear regression works with our dataset.
 After we were confident that MLR would work on our dataset, we started to implement the model. We first split the data into train and test data with a random state of 54. As it turns out later in evaluation, this random state produces a extremly high accuracy. We then scaled the each column of our data into [0,1] and then apply MLR to generate the model and produce the predicted result.
After we were confident that MLR would work on our dataset, we started to implement the model. We first split the data into train and test data with a random state of 54. As it turns out later in evaluation, this random state produces a extremly high accuracy. We then scaled the each column of our data into [0,1] and then apply MLR to generate the model and produce the predicted result.

Part 4: MLR Evaluation
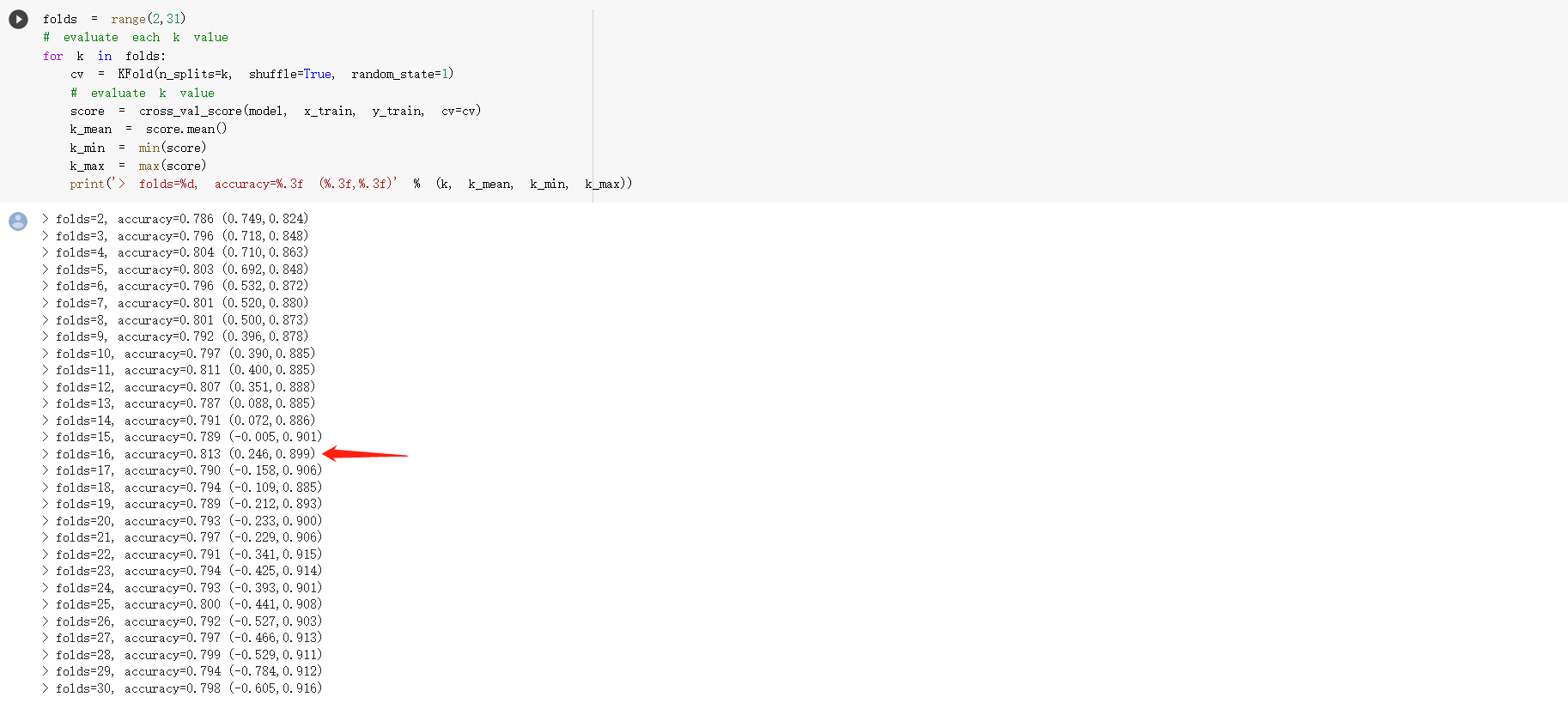
We calculate R-squared R2 (coefficient of determination) regression score to see how well our model fits the data or more precisely, measure the scatter of the data points around the fitted regression line. Best possible score is 1.0. But since our data points can be sparse, 0.68 does not mean our model is surely bad or good. We would evaluate the model in more aspects. Since R-squared can’t validate our result, we applied K-fold cross validation to check our validation score. We also tried with different K-fold values to check the validation score.

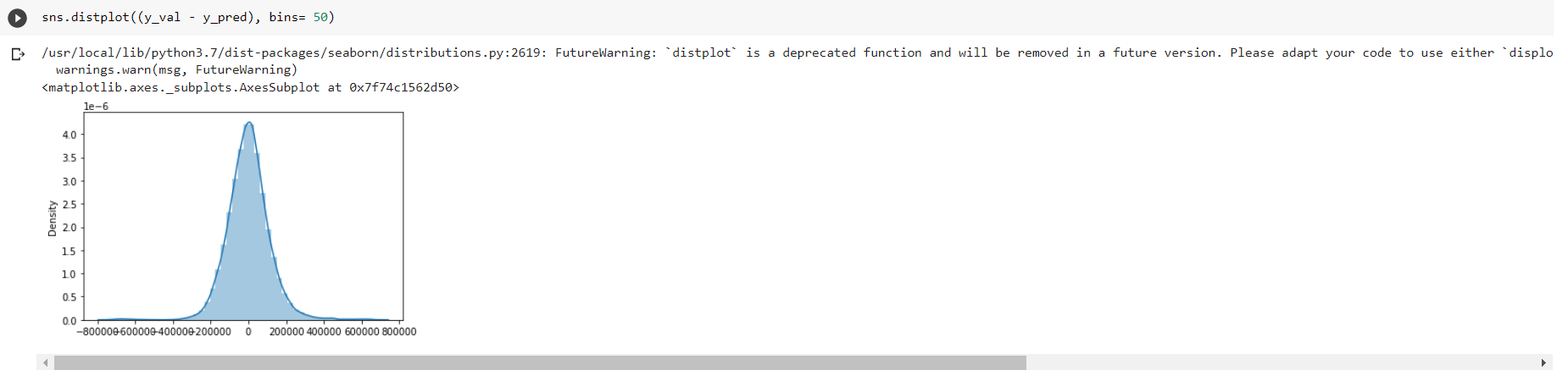
 We also calculated the difference between the predicted value and the expected value to calculate the accuracy of our result. As mentioned before, the random state gives us an extremely high accuracy at 99.509%.
We also calculated the difference between the predicted value and the expected value to calculate the accuracy of our result. As mentioned before, the random state gives us an extremely high accuracy at 99.509%.

Part 5: Conclusion
Although the accuracy for our old model (Decision tree) is high, we believe that it is beause we have choosed a good reducing method, EDA. By using thie method, we were able to reduced our data from 81 features to 25 price-related featuers, and it turns out these features are actually highly related with the housing price, giving us a 98% accuracy. However, if we reduced the features in an insufficient way, the result will be far from ideal. Therefore, we decided to find a way that can produce high accuracy predicted result without the need to reduce the features. Also, the K-folds cross validation score for our old decision tree model is also not as high.
 We tried to implement Random Forest with the cleaned but not reduced dataset and it turns out that the accuracy with random forest on unreduced dataset is also around 98%. We also tried to implement the multiple linear regression model to improve the validation score. The random forest model outperforming our old decision tree model by saving us time since we don’t need to run algorithms to generate the heat map to reduce the features and the multiple linear regression model outperforming the old decision tree model by having a higher accuracy (99% for MLR comparing to 98% for DT) and a higher validation score (0.82 for MLR comparing to 0.73 for DT). However, the new models do not outperform the old models in every category of performance metric. Randome Forest only outperforms DT in the sense of no need to reduce the features during preprocessing period. The actual accuracy for random forest did not outperforms the accuracy of DT in our dataset.
We tried to implement Random Forest with the cleaned but not reduced dataset and it turns out that the accuracy with random forest on unreduced dataset is also around 98%. We also tried to implement the multiple linear regression model to improve the validation score. The random forest model outperforming our old decision tree model by saving us time since we don’t need to run algorithms to generate the heat map to reduce the features and the multiple linear regression model outperforming the old decision tree model by having a higher accuracy (99% for MLR comparing to 98% for DT) and a higher validation score (0.82 for MLR comparing to 0.73 for DT). However, the new models do not outperform the old models in every category of performance metric. Randome Forest only outperforms DT in the sense of no need to reduce the features during preprocessing period. The actual accuracy for random forest did not outperforms the accuracy of DT in our dataset.